Absolvent študijného programu zameraného na sociálny a sémantický web na Technickej univerzite v Košiciach (TUKE) získava rozsiahle znalosti a zručnosti v oblasti informačných technológií, ktoré mu umožňujú efektívne sa uplatniť v dynamickom svete webových technológií a informačných systémov. Štúdium je koncipované tak, aby absolvent bol schopný samostatne a tvorivo riešiť komplexné problémy, navrhovať inovatívne riešenia a implementovať moderné technológie.

Profil absolventa
Absolvent študijného programu zameraného na sociálny a sémantický web na TUKE je pripravený na špecifikovanie, navrhovanie, implementáciu a údržbu rozsiahlych IT aplikácií. Ovláda programovacie jazyky C, C# a Python, čo mu umožňuje flexibilne reagovať na rôzne vývojové požiadavky. Okrem toho má hlbšie informácie z oblasti integrácie a využívania trendov v IT, ako sú Edge, Fog a Cloud technológie pre Internet všetkého (Internet of Everything).
Absolvent je schopný pracovať efektívne, flexibilne a samostatne, či už ako člen tímu alebo ako jeho vedúci. Jeho schopnosti zahŕňajú nielen technické zručnosti, ale aj schopnosť riadiť projekty, komunikovať s klientmi a spolupracovať s odborníkmi z rôznych oblastí.
Výsledky vzdelávania
Absolvent získa znalosti v oblasti webových technológií, modelovania sémantického a sociálneho webu, tvorby virtuálneho prostredia pre interaktívnu simuláciu a modelovania a riadenia procesov na virtuálnych modeloch. Taktiež získa teoretické vedomosti týkajúce sa metód vizualizácie, opisu, modelovania, simulácie a optimalizácie webových systémov a informačného zabezpečenia rozhodovacích systémov. Naučí sa implementovať moderné informačné a sieťové technológie a rozvíjať a navrhovať vlastné riešenia problémov, tvorivo aplikovať získané poznatky, efektívne sa rozhodovať pri výbere a použití metód a prostriedkov sociálneho webu a sémantických technológií.
Absolvent bude ovládať a využívať objektovo orientované programovacie jazyky, databázové systémy, počítačové siete, vizualizačné produkty a produkty pre inteligentné interakcie. Študent získa taktiež poznatky z oblasti projektovania a programovania sémanticky obohatených systémov pre hospodárske subjekty, ich nástrojov a prístupov.
Štruktúra štúdia a hodnotenie
Štúdium je rozdelené do semestrov, pričom v každom semestri študent absolvuje niekoľko predmetov. Podmienky absolvovania predmetu zahŕňajú priebežné hodnotenie (PH) a záverečné hodnotenie (ZH). Celkový výsledok sa stanoví v súlade s vnútornými predpismi TUKE.
Priebežné hodnotenie (PH)
Študent prospeje v PH a získa zápočet, ak získa minimálne 21 % zo 40 %. V priebehu semestra absolvuje zápočtový test v systéme Moodle za 10 bodov. Ďalších 30 bodov môže získať za dve zadania, ktoré spočívajú v tímovej práci na projektoch obsahujúcich návrh a implementáciu systémov sémantického a sociálneho webu.
Záverečné hodnotenie (ZH)
Študent prospeje v ZH a úspešne vykoná skúšku, ak získa minimálne 31 % zo 60 %. Skúška pozostáva z didaktického testu, pri prípadnej ústnej skúške možno získať maximálne 3 body k zlepšeniu hodnotenia.
Celkové hodnotenie (CH)
Celkové hodnotenie (CH) je suma hodnotení získaných študentom za hodnotené obdobie. Celkový výsledok sa stanoví v súlade s vnútornými predpismi TUKE.
Tematické oblasti a projekty
Štúdium zahŕňa širokú škálu tematických oblastí, ktoré sú zamerané na aktuálne trendy a technológie v oblasti sociálneho a sémantického webu. V rámci štúdia vznikla infraštruktúra poskytujúca výpočtové kapacity pre riešenie úloh v oblasti hospodárskej informatiky a priestor pre realizáciu záverečných prác študentov. Boli vytvorené elektronické materiály a služby vrátane webových portálov na podporu výučby, návodov a príručiek pre softvérové nástroje, ako aj učebnice pre predmety IT manažment a Sémantický a sociálny web. Implementovaná bola aj platforma Moodle ako e-Learningová podpora.
Príklady projektov a tém
- Predikcia výskytu nízkej oblačnosti pomocou metód dolovania v dátach.
- Modeling of Collaboration Social Network Including Temporal Attributes.
- Bezpečnosť sociálnych sietí.
- Design and implementation of incremental algorithm for creation of generalized one-sided concept lattices.
- Profitabilita analytických aplikácií databázového marketingu.
- Návrh využitia metodológie METHONTOLOGY pre aplikáciu vybraného konceptuálneho modelu.
- Porovnanie metodológií pre budovanie ontologických modelov.
- Využitie internetového marketingu pre zvýšenie predajnosti internetového obchodu.
- Predikcia bankrotu firiem pomocou vhodných metód objavovania znalostí.
- Optimalizácia procesov v stavebnej firme.
- Efektívne využívanie zdrojov vo výrobe pomocou procesného modelovania.
- Využitie vhodných webových technológií pre prezentáciu a rezerváciu ubytovacích kapacít.
- Optimalizácia výrobného procesu prostredníctvom štíhlej výroby.
- Optimalizácia výroby pomocou procesného modelovania.
- Process modeling as a supporting tool for managing of the enterprise security.
- Prečo monitorovať on-line komunikáciu?
- Aplikácia dolovania dát vo výrobnom priemysle.
- Course web site as an integrated solution for e-learning, collaboration and publicly available knowledge base.
- A review of data mining applications in manufacturing.
- Podpora rozhodovania s využitím aspektovo orientovanej analýzy sentimentu.
- Využitie ontológií v oblasti riadenia IT služieb.
- Konverzačný obsah v kontexte bezpečnosti sociálnych sietí.
- Management of enterprise security.
- Využitie dolovania dát v oblasti výroby polyamidových vláken.
- Využitie BI na analýzu finančnej situácie firiem.
- Využitie ontológií pre riadenie IT služieb v oblasti prevádzky služieb.
- Webová aplikácia pre dolovanie v dátach použitím FCA.
- Implementácia nástroja pre vizualizáciu rozhodovacích stromov v úlohách klasifikácie textových dokumentov.
- Zhlukovanie textových dokumentov algoritmom GHSOM v distribuovanom prostredí.
- Distribuovaný algoritmus Boosting pre klasifikáciu textových dokumentov.
- Od adaptívneho k sémantickému webu.
- Finding Patterns in Industrial Process Data.
- A MATLAB educational software tool for Knowledge Discovery course.
- The use of data mining to identify patterns in the industrial process data.
- Financial data analysis using suitable open-source Business Intelligence solutions.
- ICT-based Platform to Increase the Level of Elderly’s Social Inclusion.
- ICT-based Solution for Elderly People.
- Aplikácia pre podporu výučby problematiky generovania rozhodovacích stromov.
- Prieskumná analýza dát na základe logov z kolaboratívneho prostredia.
- Knowledge Discovery Methods for Bankruptcy Prediction.
- Identifikácia kritických miest procesov prostredníctvom analýzy záznamov udalostí.
- Process mining : Events and traces visualization proposal.
- Identifikácia vzťahov a väzieb v záznamoch udalostí.
- Concept Definition for Student Profile Forming.
- Concept definition for process discovery purposes.
- Identifikácia a analýza záznamov udalostí pre rozpoznávanie procesov.
- Využitie BOINC softvéru ako distribuovaného výpočtového prostredia na zvolenej infraštruktúre.
- Návrh a implementácia nástroja pre výučbu metód riešenia dopravného problému v jazyku Processing.
- Conversational content in the context of safety of social networks.
- Weighting method for student profile forming.
- Analýza a návrh vhodného modelu využitia služieb typu softvér ako služba v univerzitnom prostredí.
- Audit webovej stránky vybranej organizácie.
- Návrh, implementácia a vyhodnotenie vplyvu webového informačného systému firmy.
- Decision support system for Software as a Service applications.
- Adaptácia cloud computingu.
- Local Structure Analysis of Company Network.
- Component Identification in Company Networks.
- Design and implementation of incremental algorithm for creation of generalized onesided concept lattices.
Predmety štúdia
Študijný program zahŕňa široké spektrum predmetov, ktoré pokrývajú rôzne aspekty sociálneho a sémantického webu.
-
Programovanie nízkoúrovňových aplikácií
Cieľom predmetu je naučiť študentov samostatne vytvárať praktické aplikácie pripojenia periférnych zariadení k počítačom pre úlohy z oblasti riadenia, vizualizácie a sieťovej komunikácie medzi počítačmi a procesmi, s overením v podmienkach počítačov PC, Raspberry PI, Intel Edison a pod. Koncepcia predmetu je stavaná tak, aby po HW stránke študenti pochopili základnú architektúru počítača PC a jeho podsystémov ako napr. pamäťový podsystém, zbernice, prerušovací podsystém, systém priameho prístupu do pamäte, vizualizačný podsystém, vstupno/výstupný podsystém, zahŕňajúci štandardné rozhrania PC (RS-232, USB, a pod.), technologické rozhrania (analógový, číslicový a frekvenčný V/V, PWM a pod.), siete a sieťové rozhrania.
-
Dátové sklady a OLAP
Cieľom predmetu je naučiť študentov aplikovať prostriedky manažérskeho riadenia na báze multidimenzionálnych databáz a internetových technológií v rámci návrhu, aplikácie a využívania informačných systémov pre oblasť strategického, ekonomického a technického manažmentu. Uvedený predmet je nadstavbového charakteru. Vo väzbe na poznatky z oblasti relačných databázových systémov, distribuovaných systémov, počítačových sietí, expertných systémov a ekonomiky vytvára priestor pre získavanie informácií z informačných systémov pre manažérov na všetkých úrovniach riadenia s možnosťou požadovanej agregácie a abstrakcie, pričom automaticky získané informácie sú prezentované vo forme prehľadov, štatistík a predikcií.
-
Objektovo orientované programovanie
Cieľom predmetu je poskytnúť študentom základy objektovo-orientovaného návrhu a programovania v objektovo-orientovaných jazykoch. Po úspešnom absolvovaní tohto predmetu študenti môžu získané znalosti využiť pri návrhu a implementácii softvérových systémov použitím objektovo-orientovaných programovacích jazykov a návrhových vzorov.
-
Pokročilé metódy objavovania znalostí
Cieľom predmetu je poskytnúť študentom prehľad vedomostí a nadobudnúť praktické zručnosti pri aplikovaní pokročilých metód analýzy dát zameraných hlavne na mnohorozmerné dáta a dáta, ktoré nie sú priamo reprezentované v tabuľkovej forme. Tento predmet nadväzuje a rozširuje vedomosti získané počas štúdia v základných predmetoch Objavovania znalostí v databázach a Strojového učenia.
-
Programovanie mobilných aplikácií
Hlavným výsledkom je získanie základných znalostí z vývoja natívnych a hybridných mobilných aplikácií. Študent si predovšetkým osvojí vytvorenie praktických aplikácií vrátane komunikácie s externými zariadeniami pomocou bezdrôtovej, resp. drôtovej komunikácie. Bude schopný používať mobilnú senzoriku a efektívne pracovať s databázami, pamäťou, internými a externými úložiskami. Zároveň bude vedieť efektívne preložiť časovo náročné úlohy na pozadie, do služby alebo nového vlákna.
-
Analýza a návrh informačných systémov
Cieľom predmetu je poskytnúť študentom nielen teoretické vedomosti ale aj praktické zručnosti potrebné pri procese analýzy a návrhu informačných systémov v rôznych aplikačných doménach. Po úspešnom absolvovaní tohto predmetu študenti môžu získané znalosti a skúsenosti s jazykom UML a štandardom BPMN využiť pri riešení svojich bakalárskych prác alebo iných semestrálnych projektov orientovaných na vývoj softvérových aplikácií.
-
Spracovanie veľkých dát
Študent získa základné poznatky z oblasti spracovania veľkých dát, metód, prístupov a technológií, ktoré sa v tejto oblasti využívajú. Študent nadobudne znalosti o konceptoch gridového a cloudového počítania, o distribuovaných, NoSQL a in-memory databázových systémoch, metódach paralelného a distribuovaného počítania. Študent získa základné zručnosti pre návrh a implementáciu aplikácií pre spracovanie veľkých dát.
-
Hospodárska informatika
Cieľom predmetu je poskytnúť študentom teoretické a praktické znalosti z hospodárskej informatiky a príbuzných oblastí ako manažment inovácií (zavádzanie zmien do praxe), procesný manažment a riadenie, informačný manažment, podniková analytika, marketing (zostavovanie marketingových stratégií a plánov), podpora manažmentu prostredníctvom vhodných IT riešení, atď. Študent taktiež získa poznatky o financovaní projektov rôzneho zamerania a o vhodných grafických riešeniach, aby rozumel základným princípom tvorby projektov a práce v projektovom prostredí.
-
Manažment znalostí a informačné systémy
Jednotlivé úrovne práce so znalosťami. Dáta, informácie, znalosti, kategorizácia znalostí. Rôzne uhly pohľadu na manažment znalostí. Základná architektúra systému pre podporu manažmentu znalostí (SMZ) v organizácii a príklady konkrétnych systémov SMZ. Vyhľadávanie informácií z množiny textových dokumentov. Modely pre IR: boolovský, vektorový a pravdepodobnostný model. Predspracovanie textových dokumentov. Vyhodnocovanie systémov IR. Vyhľadávanie na webe. Faktory ovplyvňujúce manažment znalostí (MZ). Identifikácia vhodného typu riešenia manažmentom znalostí. Vplyv manažmentu znalostí (MZ) na organizáciu a hodnotenie MZ. Základné pojmy z oblasti objavovania znalostí a dolovania v dátach. Proces objavovania znalostí, metodika CRISP-DM, popis jednotlivých krokov. Metódy dolovania v dátach - prediktívne a popisné dolovanie v dátach. Objavovanie asociačných pravidiel, zovšeobecňovanie, klasifikácia, predikcia, zhlukovanie. Dátové sklady. Prehľad vybraných metód pre objavovanie znalostí. Dolovanie znalostí z kolekcií textových dokumentov. Vybrané prípadové štúdie z výskumných a vývojových projektov.
-
Manažment IT služieb
Študent získa základné poznatky z oblasti manažmentu IT služieb a súvisiacich noriem a rámcov. Študent nadobudne základné znalosti rámca ITIL, a jednotlivých princípov, konceptov a procesov, ktoré popisuje. Študent si osvojí základné myšlienky IT Governance a súvisiaceho rámca COBIT, základné vedomosti o informačnej bezpečnosti a súvisiacich normách a rámcoch.
Sémantický web
Sémantický web je web, ktorý sa má stať novým evolučným stupňom súčasného webu. Ide o web, kde sú informácie štruktúrované a uložené podľa štandardizovaných pravidiel, čo uľahčuje ich vyhľadanie a spracovanie. Myšlienku sémantického, čiže významového webu prvýkrát vyslovil Tim Berners-Lee v roku 2001, kedy upozornil na skutočnosť, že súčasný web je len spleť webových stránok, ktorá neustále rastie a v ktorej je stále zložitejšie nájsť relevantné informácie. Sémantický web je podľa neho rozšírením súčasného webu, v ktorom informácie majú pridelený dobre definovaný význam lepšie umožňujúci počítačom a ľuďom spolupracovať. Sémantický web predstavuje reprezentáciu dát na WWW.

Je založený na technológii Resource Description Framework (RDF), ktorá integruje širokú škálu aplikácií využívajúcich syntaktický zápis v XML a identifikátory URI pre pomenovanie. Základným krokom k vytvoreniu sémantického webu je konceptualizácia dát dostupných na Internete, ktorej kľúčovým nástrojom sú ontológie alebo formalizované reprezentácie znalostí určené na ich zdieľanie a znovupoužitie.
Sémantický web je založený aj na štandardizovanom popise webových zdrojov (všetko, dosiahnuteľné pomocou WWW, teda textové dokumenty, obrázky, videosekvencie, zvukové súbory a pod.). Každý zdroj by bol vybavený rovnakými charakteristickými údajmi (autor, typ zdroja, kľúčové slová atď.), čo by umožnilo užívateľom Internetu pracovať so sieťou WWW ako s relačnou databázou a pýtať sa na jej obsah prostredníctvom jazykov podobných SQL.
Technologickým základom sémantického webu by sa mal stať štandard RDF (Resource Description Framework) - všeobecný rámec pre opis, výmenu a znovupoužitie metadát. Poskytuje jednoduchý model pre opis zdrojov, ktorý nie je závislý na konkrétnej implementácii. Dátový model RDF umožní špecifikovať trojice (zdroj, vlastnosť, hodnota vlastnosti). Sémantický web propaguje Tim Berners-Lee už niekoľko rokov, napriek tomu sa doteraz nedočkal výrazného rozmachu, pravdepodobne pretože je oproti súčasnému webu príliš komplikovaný. Zmysluplnosť dát pre strojové algoritmy môžu sprostredkovať metadáta, ktoré sú vytvárané na základe existujúcich ontológií - sémantických modelov oblasti, domény. Podmienkou je možnosť odvodzovania nad danou ontológiou. Kontinuita kontextu sémantiky a inteligencie webu je naznačená v Semantic Web Report autora MillsDavis-a.
Sociálny web
Klasický web sa rozvíja v dvoch divergentných smeroch:
- Ku webu 2.0 - sociálnemu webu, ktorý zrovnoprávňuje počet producentov obsahu s počtom konzumentov (webové diskusie, zverejňovanie videí, fotografií, systémy automatickej tvorby webových stránok,...).
- Ku webu 3.0 - sémantickému webu, ktorý umožňuje sémantické vyhľadávanie, zahŕňa UI, inteligentných agentov a pod.
Sociálne siete - úvod
Interakcie každého človeka s okolitým svetom môžu byť použité ako zdroj dát pre sociálnu sieť (napríklad Blog.sme.sk). Sociálna sieť (graf) je vytvorená reláciami (spojenice) medzi používateľmi (uzly) webu. Priateľ je používateľ, ktorého autor stránky zverejnil (odkazy na jeho publikačnú činnosť) na svojej profilovej stránke, pridal si ho k priateľom na sociálne sieti. Influencer je používateľ, ktorý svojím pôsobením získa pozornosť ostatných používateľov (odkazujú sa na jeho publikačnú činnosť). V rámci sociálnych sietí rozlišujeme relácie priateľov a relácie influencerov. Tieto relácie tvoria bázu dát pre vizualizačné metódy. Vizualizácia sociálnej siete poskytuje zjednodušený (intuitívny) pohľad nad komplexnou množinou vstupných dát, ktorý zvýrazňuje vlastnosti, ktoré chceme skúmať. Analýza konvenčnými metódami je neefektívna.
Sociálne siete súčasnosti
- MySpace (www.myspace.com): Je sociálna sieť s interaktívnou štruktúrou. Je najväčšia na svete čo sa týka objemu prenesených dát a obsahuje medzinárodné osobné profily, blogy, fotografie, hudbu a videá. Najpoužívanejšie z mnohých modulov tejto siete sú: MySpaceIM, MySpaceTV, MySpaceMobile, MySpaceNews a pod. Vynálezca patentu Jonathan Abrams dostal ocenenie za systém, metodiku a aparát pre spájanie používateľov na základe priateľstva.
- Xanga (www.xanga.com): Jedna z najväčších blog portálov (používateľov viac ako 27 mil.). Vznikla v Newyork-u roku 1999 spustením služby pre čítanie recenzií na knihy a filmy, neskôr pre pridávanie blogov (expanzia).
- Hi5 (www.hi5.com): Sociálna sieť, ktorá bola derivovaná z MySpace pre tínedžerov (40 mil. použ.). Je to 8. najrozšírenejšia sociálna sieť v USA, viac profilovaná ako MySpace. Značne obľúbené: Hip Hop a R&B.

Sociálne siete - vstupné dáta
Existujú dve formy reprezentácie dát pre vizualizáciu Sociálnej siete:
- Pravouhlé zobrazenie: vyhodnotenie dát z formulárov, ankiet, prieskumov aj štatistických výskumov. Riadky reprezentujú jednotlivé prípady štúdie - entity, stĺpce ich vlastnosti alebo hodnoty meraní a bunky vyjadrujú hodnotu vlastnosti istej osoby. Odhaľuje kvantitatívne a kvalitatívne vlastnosti jednotlivých prvkov siete.
- Štvorcové zobrazenie (sieťová reprezentácia): je matica, v ktorej sú stĺpce a riadky reprezentované tými istými entitami. Bunky matice reprezentujú vzťah medzi entitami. Informuje nás o vzťahoch medzi jednotlivými prvkami siete navzájom. V štvorcovom zobrazení môžeme porovnávať riadky - zistenie podobnosti medzi osobami, lebo majú podobných priateľov; stĺpce - zistenie kto je komu podobný, lebo si ich vybrala za priateľa tá istá osoba. Ak sa v ňom nachádza približne rovnaký počet „1“ a „0“, potom má sieť priemernú hustotu obľúbenosti. Porovnaním stĺpcov a riadkov je možné určiť, či sa vo voľbách nachádza reciprocita (vzájomné priateľské vzťahy).
Sociálne siete - prvky
Sociálna sieť je reprezentovaná incidenčnou maticou B vrcholov a hrán (n x m, kde n je celkový počet vrcholov a m je počet hrán). Každý prvok bij matice B je: bij = 1 ak vrchol i je incidentný s hranou j v grafe G; bij = 0 inak. Táto reprezentácia sa nazýva matica susednosti - najjednoduchšia a najpoužívanejšia binárna forma. Takouto maticou je aj štvorcové zobrazenie. Vizualizácia matice susednosti je graf - sociálna sieť. Uzly sú entity siete a hrany reprezentujú reláciu medzi uzlami, napr. priateľ, zamestnávateľ, príbuzný, spolužiak... Na základe topológie siete a charakteru spojenia medzi uzlami rozlišujeme základné typy uzlov:
- HVIEZDA (Star, Snowflake): Je charakteristická centrálnym uzlom, na ktorý sa napájajú ostatné. Dostaneme ju ak centrálny uzol umiestnime do stredu kružnice a ostatných používateľov na kružnicu.
- MOST (Bridge): Nedominantný uzol čo do počtu spojení. Ale svojimi hranami sprostredkuje spojenie medzi inými sociálnymi sieťami.
Metódy vizualizácie sociálnych sietí
Vizualizačné metódy sa používajú v mnohých vedných oblastiach. Podľa historika Alfreda Crosbyho je jeden z dvoch faktorov (druhý je meranie), ktorým vďačíme za rozmach všetkých vedných oblastí. Bez vizualizácie (možnosti vykresliť získané údaje) by bol výskum sťažený až namáhavý.
- Kruhová hierarchická reprezentácia (Radial Hierarchical Network): vhodná pre obrovské siete (do 10 mil. uzlov). Vyvinuté spol. NicheWorks. Umožňuje siete prehľadávať interaktívne a skúmať uzly a hrany siete. Iné metódy sú buď pomalé alebo neprodukujú dostatočne výstižný výstup.
- Strom (Tree): matematika, štatistika, automatizácia, rozhodovacie stromy - vyhovujú iba striktne hierarchicky usporiadaným dátam. Koreňový uzol (root) je najsilnejší bod siete, ostatné sa hierarchicky napájajú na tento uzol a navzájom.
Vizualizácia a kontrola bezpečnosti
Vizualizácia je kľúčová pre odhalenie zraniteľností v systémoch. Príkladom je pokus o vizualizáciu systémových volaní pri zobrazení jednej stránky na dvoch webových serveroch - Apache a Microsoft IIS, čo umožňuje porovnať bezpečnosť a optimalizáciu ich behu.
Vizualizácia a optimalizácia kódu
Revízia zmien vo vyvíjanom kóde. Obraz kódu vyvíjaného softwaru sa dynamicky mení v čase. Viac vývojárov na tvorbe projektu - častejšie zmeny kódu. Problematická orientácia v dynamicky meniacom sa prostredí - metódy vizualizácie sú nápomocné. Projekt REVIOSIONIST generuje vizualizácie zmeny v štruktúrach a obsahu stránok.
Karma používateľa webu
Na portáli Blog.sme.sk sa hodnotenie používateľa derivuje z hodnotení jeho príspevkov - karma. Karma vyjadruje priemer názorov mnohých ľudí. Vyjadruje popularitu, nie kvalitu. Karma sa zvyšuje kliknutím na podobný odkaz: „Výborný text, chcem tomuto autorovi zlepšiť karmu.“
Vizualizácia priateľstiev
Priateľ je jeden možný typ používateľa webu. Mrak vyjadruje popularitu používateľov - „tool ManyEyes“. Popularita osoby je číslo udávajúce počet používateľov, ktorí vedú danú osobu ako priateľa. Vizualizácia v malom - každý používateľ má vlastnú štruktúru vyjadrujúcu jeho relácie k priateľom - Pajek.

Vizualizácia influencerov
Skúmame opačný trend - ako sa iní používatelia odkazujú na moje články. Ako ovplyvňujem ostatných obsahom svojich článkov.
Sémantická komunikácia v informačných systémoch
Sémantická komunikácia ako nový prvok v komunikácii informačných systémov (ďalej IS) má pomôcť zjednodušiť prenos informácií medzi systémami. Celkovo poskytuje vyššiu úroveň komunikácie medzi softvérovými entitami. Prvý dôležitý problém v komunikácii je definovať, aký typ dát tvorí zmysluplný obsah pre komunikované správy a akú má mať štruktúru. Syntax a sémantika môže byť väčšinou definovaná nezávisle od aplikačnej domény, takže veľká časť modelu obsahu môže byť celkom úspešne poskytovaná a kontrolovaná na úrovni strednej vrstvy (middleware). Dnešné systémy poskytujú tzv. My podrobne predstavíme model komunikácie, ktorý je založený na organizačných schémach, kategóriách obsahu, vzťahov medzi nimi a interakčných protokoloch. Tieto schémy sú zväčša aplikačne špecifické a veľká časť informácie sa drží v nich. To znamená, že komunikačný middleware poskytuje jazyky a nástroje pre definíciu ontológií.
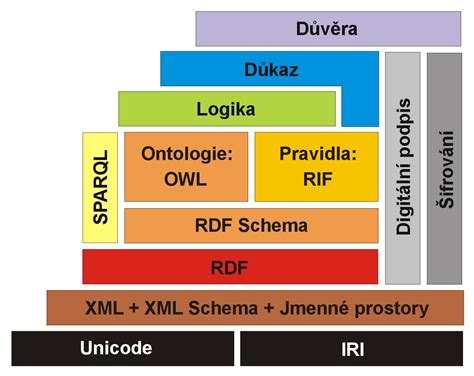
Základné princípy sémantického webu pre komunikáciu
Sémantický web je evolúcia World Wide Webu, v ktorom sú informácie spracovateľné počítačmi. Dovoľujú prehliadačom a iným softvérovým agentom ľahko hľadať a využívať informácie a spolupracovať pri ich tvorbe. No nielen počítačom, ale aj ľuďom.
- XML: poskytuje syntax pre dokumenty, ale nedefinuje sémantické obmedzenia na dokumenty.
- XML schéma: je jazyk na určenie štruktúry a obsahu XML dokumentov.
- RDF (Resource Description Framework): je jednoduchý dátový model pre referencovanie objektov (zdrojov) a definovanie ich vzťahov. Model založený na RDF môže byť vyjadrený syntaxou XML.
- RDF schéma: definuje slovník pre popis vlastností a tried RDF zdrojov so sémantikou pre všeobecné hierarchie vlastností a tried.
- OWL (Ontology Web Language): pridáva nové slovníky na popis vlastností a tried: medzi inými vzťahy medzi triedami, kardinality, rovnosť, bohatšie typovanie vlastností, charakteristiky vlastností (napr. symetriu) a enumerované triedy. OWL jazyk poskytuje tri základné triedy, ktoré poskytujú rôzne možnosti, čo sa týka vyjadrovacej schopnosti a výpočtovej zložitosti automatizovaného odvodzovania.
- OWL Lite: pre základné potreby klasifikácie hierarchie a jednoduché obmedzenia.
- OWL DL: pre maximálnu vyjadrovaciu schopnosť pri zachovaní výpočtovej kompletnosti (všetky uzávery sú garantované ako spočítateľné). DL vychádza z popisnej logiky.
- OWL Full: pre maximálnu vyjadrovaciu schopnosť bez vypočítateľných záruk.
- Rules/Queries: sú popísateľné napríklad jazykom SPARQL na definovanie dotazov.
Výhody použitia princípov sémantického webu
Princípy sémantického webu sa začínajú používať pri ukladaní dát v moderných informačných systémoch, pretože prinášajú množstvo výhod. Hlavnou a už spomenutou výhodou je možnosť spracovania takto uložených informácií počítačmi. Ďalšou výhodou je možnosť inferovania (odvodzovania) nových faktov z už existujúcich faktov alebo dokazovanie faktov. Táto funkcionalita je poskytovaná dvoma najvyššími vrstvami sémantického webu (logic, proof). Uvedieme príklad na odvodzovaciu schopnosť, ktorá vychádza z pridaní, ktoré prináša OWL, ako je tranzitívnosť alebo symetria. Napríklad, ak je Karel Čapek autorom knihy R.U.R., a jazyk knihy R.U.R. je český, pomocou odvodzovania sme schopní získavať nové fakty. Sémantický web však nedefinuje spôsob výmeny faktov, teda mechanizmus, akým rôzne informačné systémy komunikujú.
Viacvrstvový komunikačný model
Pre účely komunikácie medzi systémami treba rozoznať vrstvy, ktoré sú v informačných systémoch priamo alebo nepriamo implementované. Každá vrstva pridáva nové obmedzenia, ktoré sú aplikované pri komunikácii. Tieto obmedzenia špecifikujú hranice interakčného priestoru, v rámci ktorého všetky následné vrstvy musia operovať. Vonkajšia vrstva interakcie je zodpovedná za mechanizmus presunu správ: adresovanie komunikačných entít, zabalenie obsahu a mechanizmus front správ. Najvnútornejšia vrstva predpokladá, že každá komunikačná entita obsahuje úplný model toho, ako pracujú ostatné entity, a to aj vrátane interného spracovania informácií.
Sémantická komunikácia sa zaoberá vnútornými tromi vrstvami, teda vrstvením štruktúrovanejšieho modelu správ bez toho, aby interagujúce entity poznali vnútornosti toho druhého.
- Lingvistická vrstva: definuje všeobecnú taxonómiu v akejkoľvek aplikačnej doméne a klasifikuje správy izolovane. Táto taxonómia je inšpirovaná myšlienkami výskumu Agentových Komunikačných Jazykov (ACLs), presnejšie špecifikáciou FIPA ACL. Rôzne typy možných správ vychádzajú z rôznych druhov rečových aktov: požiadavka, oznámenie, sľub a pod.
- Performatíva REQUEST: Odoslaná, keď entita požaduje vykonanie akcie, ktorá musí byť popísaná v obsahu správy.
- Performatíva NOTIFY: Odoslaná, keď zdroj chce informovať o niečom, čo sa stalo.
- Performatíva ASK-IF: Vyžaduje v obsahu správy len udalosť, na ktorú je smerovaný dotaz.
- Performatíva ASK-WHICH: Obsahom je nekompletná udalosť, používa sa pre otvorené otázky podobne ako logické premenné v Prologu.
- Doménová vrstva: definuje obmedzenia a podmienky pre schémy obsahu správ. Vlastné schémy sú aplikačne špecifické, ale podriaďujú sa množine spoločných pravidiel s ohľadom na ich definíciu. Pre definovanie doménovej ontológie bol zvolený jazyk OWL (Ontology Web Language). Takáto ontológia rozširuje doménovo nezávislú komunikačnú ontológiu s troma základnými entitami: doménové akcie, doménové udalosti a doménové popisy objektov.
- Sociálna vrstva: spája viacero správ za účelom vybudovania ucelenej konverzácie. Toto spojenie sa nazýva interakčným protokolom.
- Žiadosť o vykonanie akcie: Priama aplikácia vyvolania príkazu, kde iniciátor vyžaduje vykonanie akcie a vykonávateľ je schopný akciu vykonať, ale má možnosť odmietnuť.
- Oznámenie udalosti: Jednosmerná a nepotvrdzovaná komunikácia, kde iniciátor jedná ako zdroj udalosti a neočakáva výsledok ani potvrdenie doručenia.
- Dotazová interakcia (ASK): Pre dotazovanie informácií, modelovaná ako rečový akt REQUEST s iným rečovým aktom ako argumentom. V otvorených otázkach s performatívou ASK-WHICH dotazovateľ má štruktúrovanú šablónu s potrebnou informáciou, ale s neznámymi časťami.
Hlavný prínos spočíva v použití viacvrstvového komunikačného modelu. Systémy komunikujúce v takomto modeli sú vzájomne tak kompatibilné, koľko vrstiev majú spoločných. Na rozdiel od často používaných komunikačných systémov (RMI, IIOP, …), ktoré používajú takzvaný “flat” systém pri komunikácii, teda buď si všetky strany komunikácie rozumejú úplne alebo vôbec, systém sémantickej komunikácie umožňuje jednotlivým elementom v informačnom systéme rozumieť komunikácii aspoň z časti aj v prípade, kedy nie je úplne známy obsah. Ako analógiu na vysvetlenie uvediem príklad z lekárskeho prostredia, kedy pacient sediaci v čakárni počuje dvoch lekárov ako sa zhovárajú o diagnóze. Pacient pravdepodobne nepozná úplný význam slov, ktoré používajú no aj napriek tomu je schopný identifikovať, či sa jeden lekár toho druhého niečo pýta, či dostal odpoveď na otázku alebo nedostal. Teda pacient a lekári majú spoločný komunikačný model len po úroveň lingvistickej vrstvy. Použitie takejto komunikácie medzi informačnými systémami prináša množstvo výhod. Inou výhodou použitia sémantickej komunikácie je ak systémy nemajú spoločný doménový model. Teda prijímateľ správy typu REQUEST je schopný túto správu prijať a identifikovať, že odosielateľ správy žiada vykonanie akcie.
Popísaný systém komunikácie bol implementovaný v multiagentovej platforme LS/TS ako modul SemCom. Umožňuje elementom komunikácie (agentom) komunikovať s použitím sémantickej komunikácie. V systéme je zadefinovaná základná ontológia a typ správ s performatívami tak ako je to popísané v tomto článku.
tags: #socialny #a #semanticky #web #tuke